
Avec l’arrivée de DALL-E 3 gratuitement sur Bing Chat début octobre, puis dans ChatGPT (pour les abonnés payants), la création d’images générées par l’intelligence artificielle s’est popularisée. Tout le monde peut désormais “créer” des images à partir d’une simple description textuelle. La porte ouverte à une créativité sans limites… exceptées celles intrinsèques à DALL-E 3. La preuve en images (nul besoin de préciser qu’aucun humain n’a été exploité dans la création de ces illustrations !).
Qu’est-ce que DALL-E ?
DALL-E est un programme d’intelligence générative conçu par OpenAI (le créateur de Chat-GPT) dont la première version a été lancée début 2021. Son nom provient du mariage entre « DALI » (le célèbre artiste surréaliste) et « WALL-E » (le robot du film d’animation de Pixar). Il a été formé pour transformer les descriptions textuelles (le prompt) en images. Par exemple, si vous lui demandez de générer « un chat à deux têtes jouant du piano », DALL-E est capable de créer une image qui représente exactement cela.

Comment fonctionne DALL-E ?
DALL-E 3 est basé sur l’architecture GPT, qui est principalement utilisée pour les tâches liées au texte. OpenAI a adapté cette architecture pour traiter les images. Le modèle a été entraîné sur un très grand nombre d’images et leurs descriptions correspondantes, lui permettant d’apprendre comment certaines caractéristiques textuelles se traduisent visuellement.
Lorsqu’il reçoit une description textuelle, DALL-E 3 génère plusieurs versions d’une image correspondante en utilisant les connaissances qu’il a accumulées pendant son entraînement.
Concrètement, le fonctionnement de DALL-E repose sur un réseau neuronal appelé CLIP (Contrastive Language–Image Pre-training). Lors de son entraînement, ce dernier a encodé des paires (image/texte) et calculé un score de pertinence entre un texte et une image. Cela lui permet d’évaluer à quel point un texte représente une image en comparant les scores de différentes images pour un même texte.
Lorsqu’on lui propose un prompt, DALL-E décompose d’abord la description textuelle pour en obtenir une représentation vectorielle (embedding de texte).
Un modèle de diffusion (prior) vient « traduire » l’embedding de texte pour générer un embedding d’image. Il transforme ainsi le texte en une image à partir d’un motif de points aléatoires et modifie progressivement ce motif vers une image lorsqu’il reconnaît des aspects spécifiques de cette image.
En dernier lieu, DALL-E procède à un mapping pour répondre à tous les éléments sémantiques de la description.
Limites des images créées par DALL-E 3
Malgré ses performances impressionnantes, DALL-E 3 présente des limites à la création de différents niveaux, des limites éthiques posées par Open AI ainsi que des limites liées au fonctionnement de Learning Machine de DALL-E 3.
Les limites liées à l’éthiques
Pour éviter les abus et la désinformation, OpenAI a souhaité dès la conception de son outil de génération d’images, brider ses contenus en limitant la capacité de DALL-E 3 à générer des images contraires à l’éthique et la morale voire même illégales, telles que :
- Les contenus explicites ou offensants : cela inclut des images à caractère pornographique, violent, haineux ou discriminatoire.
- La désinformation ou les deepfakes : pour éviter la propagation de fausses informations sur les réseaux sociaux comme X, ou la création de contenus trompeurs, Open AI utilise des techniques avancées empêchant la génération photoréaliste de visages d’individus réels, y compris ceux de personnalités publiques.
- Le contenu protégé par des droits d’auteur : bien que DALL-E génère des images originales, il est programmé pour éviter de reproduire des images ou des motifs spécifiques qui sont protégés. “DALL·E 3 est conçu pour décliner les demandes qui demandent une image à la manière d’un artiste vivant. Les créateurs peuvent désormais également retirer leurs images de la formation de nos futurs modèles de génération d’images”. annonce Open AI sur son blog.
En pratique, DALL-E bloque toute demande entrant en conflit avec sa stratégie de contenu.
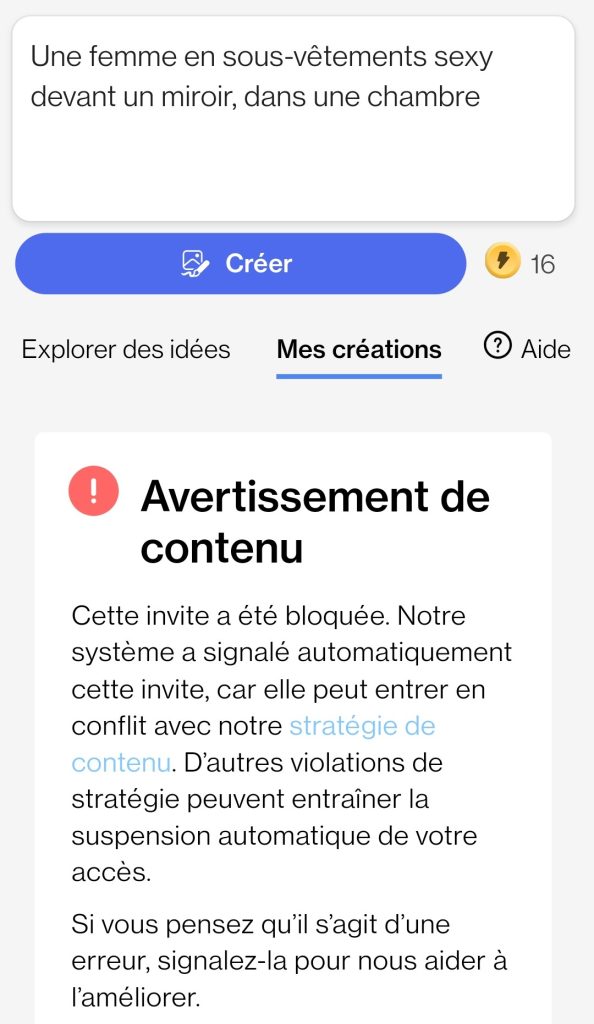
Les limites de la Learning Machine DALL-E 3
Malgré les garde-fous posés par les créateurs de DALL-E 3, les utilisateurs peuvent être confrontés à des limites intrinsèques au fonctionnement de DALL-E 3, qui ne fait qu’apprendre à partir de contenus existants. Différents biais se retrouvent ainsi dans les images générées par DALL-E 3 :
Le biais du réalisme
DALL-E génère des images en fonction de ce qu’il a appris dans son ensemble de données d’entraînement, par conséquent, il peut créer des images de choses qui n’existent pas dans la réalité. Certaines images peuvent ainsi sembler plausibles, au premier abord alors qu’elles ne sont pas du tout réalistes, les mains peuvent avoir 6 doigts, les corps traverser des objets…
Ici, l’erreur est évidente.

La scène ci-dessous, générée par le prompt “Une cage est posée sur une table dans une pièce vide. Un oiseau s’échappe de la cage et se dirige vers la fenêtre” semble réaliste. Pourtant, on pourrait jouer au jeu de 7 erreurs avec cette image !

- La cage a deux portes.
- La tringle à rideaux est confondue avec la moulure du mur.
- La fenêtre ouverte conserve les barreaux des carreaux.
- La perspective du livre posé sur la table est mauvaise.
- Le pied de la chaise se confond avec le pied de la table.
- Les ombres sont discutables.
- Il y a deux oiseaux alors que le prompt n’en indique qu’un seul.
Le biais sexiste
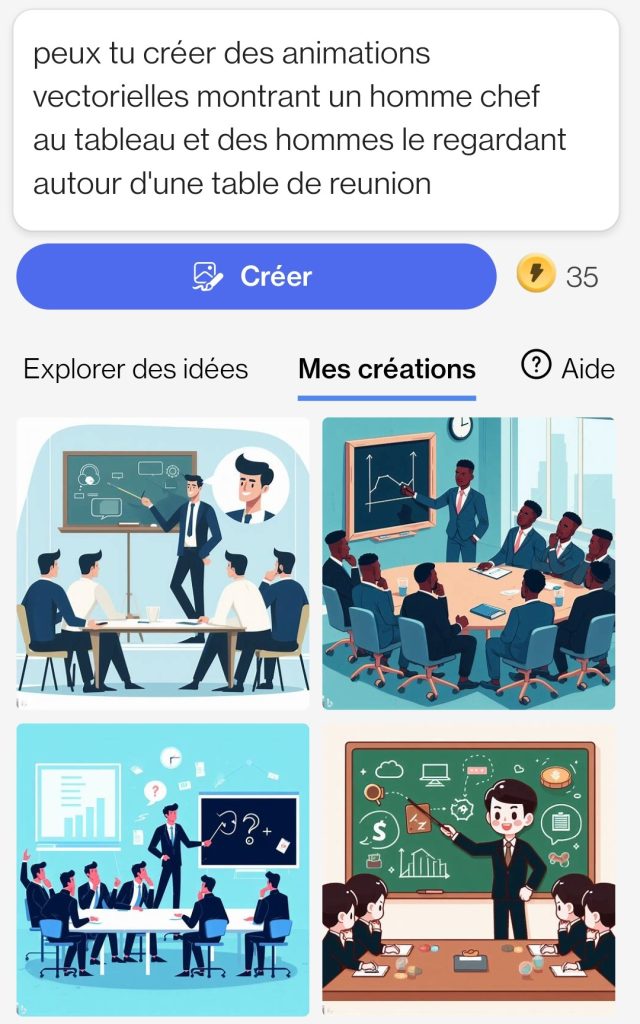
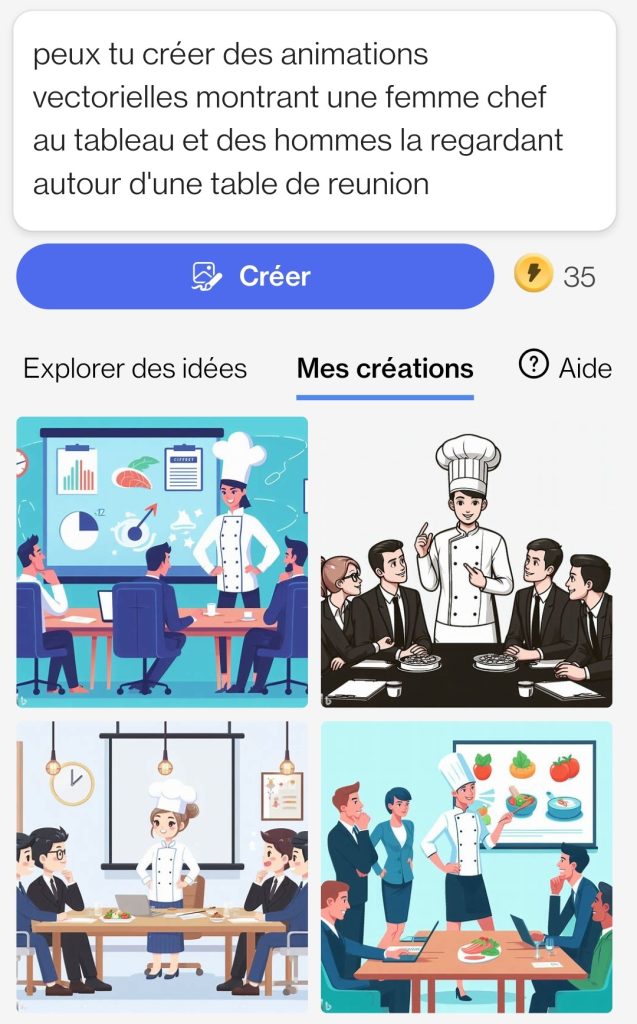
DALL-E n’interprète pas le sens des mots, ni le contexte, son algorithme se base sur l’analyse du grand nombre d’images qui lui ont été fournies en phase d’entraînement. Si bien que certaines images proposées sont empreintes du sexisme latent véhiculé par Internet.
A gauche : les images produites par DALL-E 3 en réponse au prompt “Un homme chef au tableau et des hommes le regardant autour d’une table de réunion”. A droite, les images produites par DALL-E 3 en remplaçant homme par femme dans le prompt précédent.
Le biais culturel
De même pour certains sujets plus locaux. DALL-E aura des difficultés à générer des images pour lesquelles il n’a que peu d’images référentes, pour les images parlant de vide-grenier, un concept très franco-français par exemple.
Lorsqu’on lui demande une image pour illustrer un sondage mené auprès des Français, l’outil y va des clichés bleu-blanc-rouge (avé la marinière).
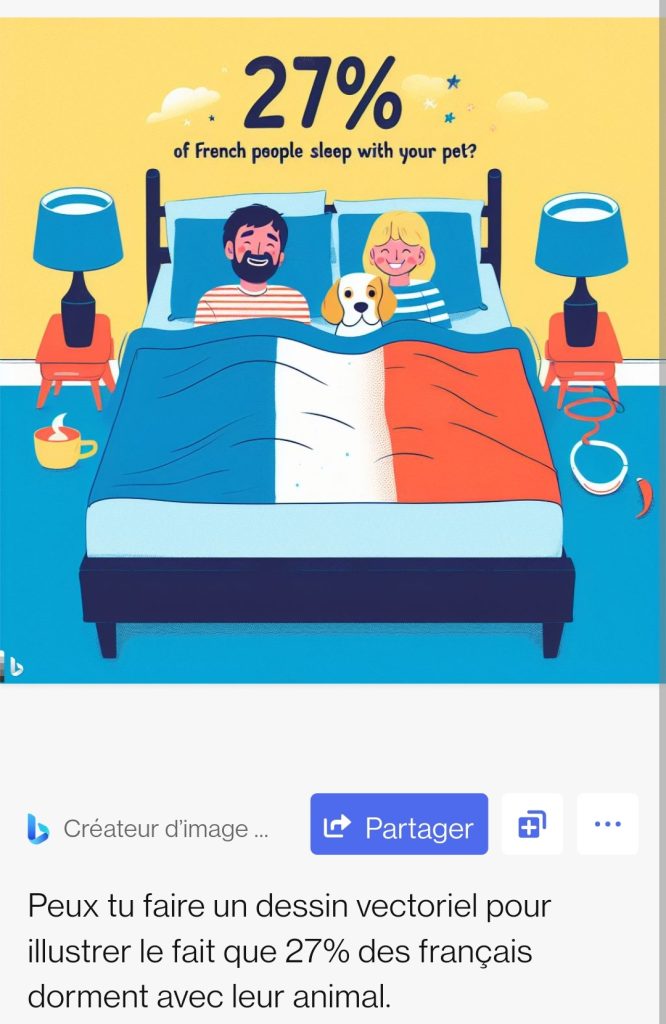
Notez la petite erreur de traduction, DALL-E ayant des difficultés à intégrer un texte ou des chiffres dans ses créations. L’outil ayant été entraîné en anglais, les prompts rédigés dans la langue de Shakespeare sont sans doute mieux suivis et plus à même d’intégrer des nuances.
Conseils pour bien utiliser Dall-E 3
Les résultats de DALL-E sont étroitement liés à la qualité de la description textuelle fournie. Des descriptions vagues ou mal formulées peuvent conduire à des résultats imprécis ou inattendus.
Le mieux placé pour nous expliquer comment rédiger un prompt pour DALL-E 3 est évidemment Chat GPT ! Nous lui avons donc demandé comment créer un prompt efficace pour DALL-E 3. Voici sa réponse :
Créer un prompt efficace pour DALL-E 3 nécessite une description détaillée et précise afin d’obtenir une image pertinente et de qualité. Voici une structure de prompt que vous pouvez utiliser comme point de départ, suivie d’un exemple pour illustrer son application :
Structure de prompt pour Dall-E 3
« [Type d’image (ex. : illustration, infographie, etc.)] représentant [sujet principal] avec [éléments spécifiques, couleurs, style, ambiance, émotions générées etc.] pour un article sur [titre ou sujet de l’article]. »
Exemple de prompt pour Dall-E 3
« Photo réaliste d’une femme utilisant un ordinateur portable dans un bureau situé dans sa maison, avec des tons verts et bleus gris, dans une ambiance sereine, pour un article sur ‘Les tendances du télétravail en 2023’. »
Perfectionner ses prompts pour DALL-E 3
La génération d’image avec DALL-E impose les mêmes précautions que la génération de textes avec CHAT-GPT. Dans un premier temps, l’utilisation d’un prompt détaillé et précis donnera à DALL-E toutes les chances de générer une image qui correspond à vos attentes.. Si ce n’est pas le cas, c’est que vous l’avez mal guidé ! Pour vous aider, pensez à fournir les détails suivants :
- Type d’image
Indiquez clairement si vous souhaitez une illustration, une infographie, une photo réaliste, etc.
- Détails visuels
Plus vous fournissez de détails sur l’apparence souhaitée, plus l’image générée sera proche de votre vision.
- Ambiance et style
Cela aide DALL-E à comprendre le ton général de l’image. Par exemple, voulez-vous quelque chose de joyeux, sombre, minimaliste, détaillé, etc. ?
- Finalité
Indiquer le contexte d’utilisation (par exemple, pour un article) peut aider à orienter la pertinence de l’image.
Le rôle central de l’humain dans l’IA
Gardez à l’esprit que DALL-E 3 ne “pense pas”, ce n’est qu’un algorithme. La création d’images avec DALL-E 3 peut nécessiter de l’expérimentation et de l’apprentissage, ce que l’on appelle l’itération. N’hésitez pas à expérimenter avec différents prompts ou à ajuster les détails pour affiner les résultats selon vos besoins. Plus vous utiliserez le modèle, plus vous comprendrez ses capacités et ses limites, ce qui vous aidera à améliorer vos compétences dans la création d’images.
Tout comme les textes créés par Chat-GPT ont besoin de la relecture d’un rédacteur, les images générées par DALL-E 3 ne peuvent se passer de l’œil attentif d’un humain pour vérifier les proportions des personnages, y apporter des retouches, y ajouter la patte graphique de l’entreprise. Soignez vos images dans la mesure où, le créateur de contenu, c’est vous, les images générées par l’AI n’étant soumises à aucun droit d’auteur, pour l’instant…